 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Contrast to Consistency: Rethinking Event-based Continuous-Time Optical Flow Estimation
May 26, 2026Estimating continuous optical flow is a fundamental yet challenging problem in dynamic visual perception. Event-based cameras, with microsecond latency and high dynamic range, capture brightness changes asynchronously, offering a unique opportunity to model motion with fine temporal precision. However, the scarcity of temporally dense ground-truth annotations limits the effectiveness of supervised learning, while contrast maximization (CM) frameworks, focused on sharpening the Image of Warped Events (IWE), often neglect temporal continuity and structural coherence, leading to distorted trajectories under complex motion. To overcome these challenges, we propose a hybrid-supervised framework for continuous-time optical flow estimation, grounded in the principle of Spatio-temporal Structural Consistency (STSC). This paradigm jointly enforces local structural stability and trajectory continuity, ensuring physically coherent motion across time. To further enhance representation and robustness, we design a bidirectionally complementary multi-scale architecture and employ a curriculum-guided hybrid training strategy, enabling a smooth transition from supervised point constraints to self-supervised manifold regularization. Comprehensive experiments across multiple benchmarks show that our method achieves state-of-the-art performance in both continuous-time and standard optical flow estimation, demonstrating the effectiveness of the proposed learning paradigm.
SimInsert: Seamless Video Object Insertion via Regional Sparse Attention Fusion
May 22, 2026Video object insertion requires ensuring spatio-temporal coherence and interactive realism, extending far beyond simple content placement. However, current approaches are often hindered by a reliance on explicit motion engineering or resource-intensive retraining, restricting their flexibility and generalization. To bridge this gap, we present \textit{SimInsert}, a training-free paradigm that efficiently decouples the task into intuitive single-frame editing and semantic motion description. By harnessing the robust generative priors of image-to-video diffusion models, SimInsert propagates edits temporally, strictly preserving background invariance while enabling plausible, text-driven interactions between the inserted object and the dynamic environment. Our approach hinges on non-invasive guidance mechanisms that enforce structural consistency, facilitate seamless boundary fusion, and counteract the fidelity drift that typically accumulates during the denoising trajectory. Extensive quantitative experiments validate our efficacy: SimInsert surpasses state-of-the-art methods with an 18.8\% gain in PSNR, 20.1\% in SSIM, and a 44.1\% decrease in LPIPS, offering a streamlined solution for high-fidelity video editing.
PhysCodeBench: Benchmarking Physics-Aware Symbolic Simulation of 3D Scenes via Self-Corrective Multi-Agent Refinement
Apr 26, 2026Physics-aware symbolic simulation of 3D scenes is critical for robotics, embodied AI, and scientific computing, requiring models to understand natural language descriptions of physical phenomena and translate them into executable simulation environments. While large language models (LLMs) excel at general code generation, they struggle with the semantic gap between physical descriptions and simulation implementation. We introduce PhysCodeBench, the first comprehensive benchmark for evaluating physics-aware symbolic simulation, comprising 700 manually-crafted diverse samples across mechanics, fluid dynamics, and soft-body physics with expert annotations. Our evaluation framework measures both code executability and physical accuracy through automated and visual assessment. Building on this, we propose a Self-Corrective Multi-Agent Refinement Framework (SMRF) with three specialized agents (simulation generator, error corrector, and simulation refiner) that collaborate iteratively with domain-specific validation to produce physically accurate simulations. SMRF achieves 67.7 points overall performance compared to 36.3 points for the best baseline among evaluated SOTA models, representing a 31.4-point improvement. Our analysis demonstrates that error correction is critical for accurate physics-aware symbolic simulation and that specialized multi-agent approaches significantly outperform single-agent methods across the tested physical domains.
FreeControl: Efficient, Training-Free Structural Control via One-Step Attention Extraction
Nov 07, 2025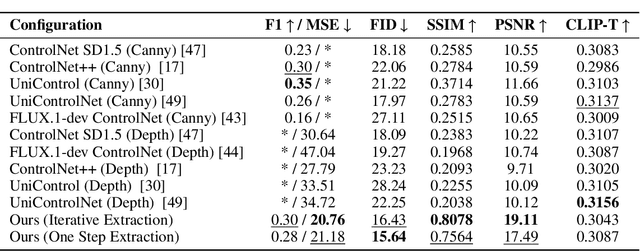
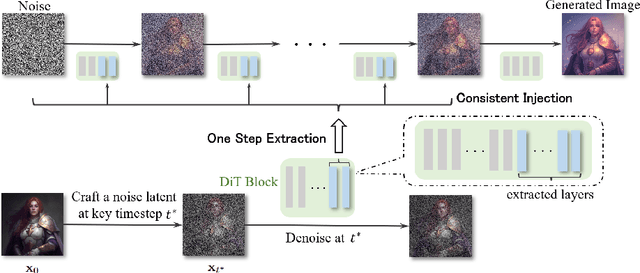
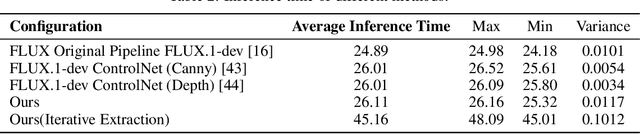

Controlling the spatial and semantic structure of diffusion-generated images remains a challenge. Existing methods like ControlNet rely on handcrafted condition maps and retraining, limiting flexibility and generalization. Inversion-based approaches offer stronger alignment but incur high inference cost due to dual-path denoising. We present FreeControl, a training-free framework for semantic structural control in diffusion models. Unlike prior methods that extract attention across multiple timesteps, FreeControl performs one-step attention extraction from a single, optimally chosen key timestep and reuses it throughout denoising. This enables efficient structural guidance without inversion or retraining. To further improve quality and stability, we introduce Latent-Condition Decoupling (LCD): a principled separation of the key timestep and the noised latent used in attention extraction. LCD provides finer control over attention quality and eliminates structural artifacts. FreeControl also supports compositional control via reference images assembled from multiple sources - enabling intuitive scene layout design and stronger prompt alignment. FreeControl introduces a new paradigm for test-time control, enabling structurally and semantically aligned, visually coherent generation directly from raw images, with the flexibility for intuitive compositional design and compatibility with modern diffusion models at approximately 5 percent additional cost.
ClinicalGPT-R1: Pushing reasoning capability of generalist disease diagnosis with large language model
Apr 15, 2025Recent advances in reasoning with large language models (LLMs)has shown remarkable reasoning capabilities in domains such as mathematics and coding, yet their application to clinical diagnosis remains underexplored. Here, we introduce ClinicalGPT-R1, a reasoning enhanced generalist large language model for disease diagnosis. Trained on a dataset of 20,000 real-world clinical records, ClinicalGPT-R1 leverages diverse training strategies to enhance diagnostic reasoning. To benchmark performance, we curated MedBench-Hard, a challenging dataset spanning seven major medical specialties and representative diseases. Experimental results demonstrate that ClinicalGPT-R1 outperforms GPT-4o in Chinese diagnostic tasks and achieves comparable performance to GPT-4 in English settings. This comparative study effectively validates the superior performance of ClinicalGPT-R1 in disease diagnosis tasks. Resources are available at https://github.com/medfound/medfound.
Targetless Intrinsics and Extrinsic Calibration of Multiple LiDARs and Cameras with IMU using Continuous-Time Estimation
Jan 06, 2025



Accurate spatiotemporal calibration is a prerequisite for multisensor fusion. However, sensors are typically asynchronous, and there is no overlap between the fields of view of cameras and LiDARs, posing challenges for intrinsic and extrinsic parameter calibration. To address this, we propose a calibration pipeline based on continuous-time and bundle adjustment (BA) capable of simultaneous intrinsic and extrinsic calibration (6 DOF transformation and time offset). We do not require overlapping fields of view or any calibration board. Firstly, we establish data associations between cameras using Structure from Motion (SFM) and perform self-calibration of camera intrinsics. Then, we establish data associations between LiDARs through adaptive voxel map construction, optimizing for extrinsic calibration within the map. Finally, by matching features between the intensity projection of LiDAR maps and camera images, we conduct joint optimization for intrinsic and extrinsic parameters. This pipeline functions in texture-rich structured environments, allowing simultaneous calibration of any number of cameras and LiDARs without the need for intricate sensor synchronization triggers. Experimental results demonstrate our method's ability to fulfill co-visibility and motion constraints between sensors without accumulating errors.
WSI-LLaVA: A Multimodal Large Language Model for Whole Slide Image
Dec 03, 2024



Recent advancements in computational pathology have produced patch-level Multi-modal Large Language Models (MLLMs), but these models are limited by their inability to analyze whole slide images (WSIs) comprehensively and their tendency to bypass crucial morphological features that pathologists rely on for diagnosis. To address these challenges, we first introduce WSI-Bench, a large-scale morphology-aware benchmark containing 180k VQA pairs from 9,850 WSIs across 30 cancer types, designed to evaluate MLLMs' understanding of morphological characteristics crucial for accurate diagnosis. Building upon this benchmark, we present WSI-LLaVA, a novel framework for gigapixel WSI understanding that employs a three-stage training approach: WSI-text alignment, feature space alignment, and task-specific instruction tuning. To better assess model performance in pathological contexts, we develop two specialized WSI metrics: WSI-Precision and WSI-Relevance. Experimental results demonstrate that WSI-LLaVA outperforms existing models across all capability dimensions, with a significant improvement in morphological analysis, establishing a clear correlation between morphological understanding and diagnostic accuracy.
E-Motion: Future Motion Simulation via Event Sequence Diffusion
Oct 11, 2024Forecasting a typical object's future motion is a critical task for interpreting and interacting with dynamic environments in computer vision. Event-based sensors, which could capture changes in the scene with exceptional temporal granularity, may potentially offer a unique opportunity to predict future motion with a level of detail and precision previously unachievable. Inspired by that, we propose to integrate the strong learning capacity of the video diffusion model with the rich motion information of an event camera as a motion simulation framework. Specifically, we initially employ pre-trained stable video diffusion models to adapt the event sequence dataset. This process facilitates the transfer of extensive knowledge from RGB videos to an event-centric domain. Moreover, we introduce an alignment mechanism that utilizes reinforcement learning techniques to enhance the reverse generation trajectory of the diffusion model, ensuring improved performance and accuracy. Through extensive testing and validation, we demonstrate the effectiveness of our method in various complex scenarios, showcasing its potential to revolutionize motion flow prediction in computer vision applications such as autonomous vehicle guidance, robotic navigation, and interactive media. Our findings suggest a promising direction for future research in enhancing the interpretative power and predictive accuracy of computer vision systems.
MixPolyp: Integrating Mask, Box and Scribble Supervision for Enhanced Polyp Segmentation
Sep 25, 2024



Limited by the expensive labeling, polyp segmentation models are plagued by data shortages. To tackle this, we propose the mixed supervised polyp segmentation paradigm (MixPolyp). Unlike traditional models relying on a single type of annotation, MixPolyp combines diverse annotation types (mask, box, and scribble) within a single model, thereby expanding the range of available data and reducing labeling costs. To achieve this, MixPolyp introduces three novel supervision losses to handle various annotations: Subspace Projection loss (L_SP), Binary Minimum Entropy loss (L_BME), and Linear Regularization loss (L_LR). For box annotations, L_SP eliminates shape inconsistencies between the prediction and the supervision. For scribble annotations, L_BME provides supervision for unlabeled pixels through minimum entropy constraint, thereby alleviating supervision sparsity. Furthermore, L_LR provides dense supervision by enforcing consistency among the predictions, thus reducing the non-uniqueness. These losses are independent of the model structure, making them generally applicable. They are used only during training, adding no computational cost during inference. Extensive experiments on five datasets demonstrate MixPolyp's effectiveness.
Generalize Polyp Segmentation via Inpainting across Diverse Backgrounds and Pseudo-Mask Refinement
May 21, 2024Inpainting lesions within different normal backgrounds is a potential method of addressing the generalization problem, which is crucial for polyp segmentation models. However, seamlessly introducing polyps into complex endoscopic environments while simultaneously generating accurate pseudo-masks remains a challenge for current inpainting methods. To address these issues, we first leverage the pre-trained Stable Diffusion Inpaint and ControlNet, to introduce a robust generative model capable of inpainting polyps across different backgrounds. Secondly, we utilize the prior that synthetic polyps are confined to the inpainted region, to establish an inpainted region-guided pseudo-mask refinement network. We also propose a sample selection strategy that prioritizes well-aligned and hard synthetic cases for further model fine-tuning. Experiments demonstrate that our inpainting model outperformed baseline methods both qualitatively and quantitatively in inpainting quality. Moreover, our data augmentation strategy significantly enhances the performance of polyp segmentation models on external datasets, achieving or surpassing the level of fully supervised training benchmarks in that domain. Our code is available at https://github.com/497662892/PolypInpainter.